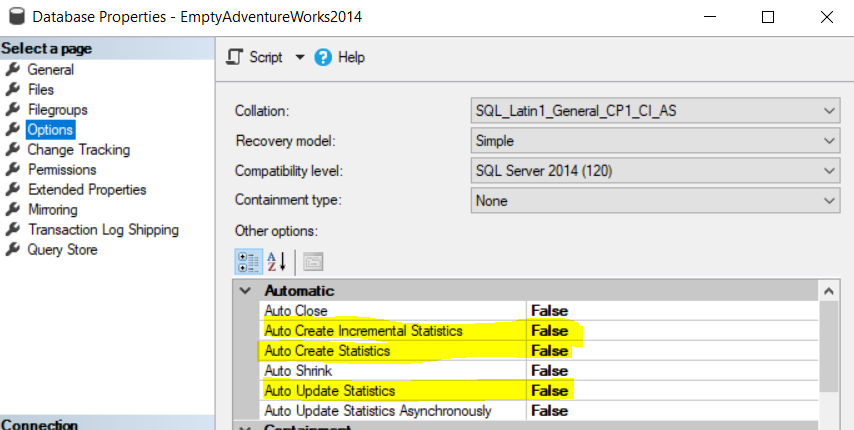
If you set up a replication – for example, a snapshot replication to refresh the ACC environment with PROD data – a correction of the identities is needed for the applications to run correctly.
The code below checks the identities and gives the syntax to correct the identity values:
SELECT
IDENT_SEED(TABLE_SCHEMA+’.’+TABLE_NAME) AS Seed,
IDENT_INCR(TABLE_SCHEMA+’.’+TABLE_NAME) AS Increment,
IDENT_CURRENT(TABLE_SCHEMA+’.’+TABLE_NAME) AS Current_Identity,
TABLE_SCHEMA+’.’+TABLE_NAME as table_name,
‘DBCC CHECKIDENT(”’+TABLE_SCHEMA+’.’+TABLE_NAME+”’, RESEED, ‘+CAST(IDENT_CURRENT(TABLE_SCHEMA+’.’+TABLE_NAME) +1 AS VARCHAR(10))+’)’ as Command
FROM
INFORMATION_SCHEMA.TABLES
WHERE
OBJECTPROPERTY(OBJECT_ID(TABLE_SCHEMA+’.’+TABLE_NAME), ‘TableHasIdentity’) = 1
AND TABLE_TYPE = ‘BASE TABLE’
AND TABLE_NAME not like ‘Mspeer%’
AND TABLE_NAME not in (‘sysarticles’,’syspublications’)
ORDER BY TABLE_SCHEMA, TABLE_NAME