When SQLserver needs to create an executionplan to retrieve data from a table, it checks if it can use an index. Sometimes it will choose an index, sometimes a full tablescan. The threshold for this decision is not the portion of rows, but the portion of 8k pages of the table. An old rule of thumb said that if around 30% of the number of pages of a table are to be retrieved, the query will not use an index, but a tablescan.
You can tamper with the statistics concerning the number of pages and rows with the little known clause of the update statistics command:
UPDATE STATISTICS WITH pagecount = 1000000
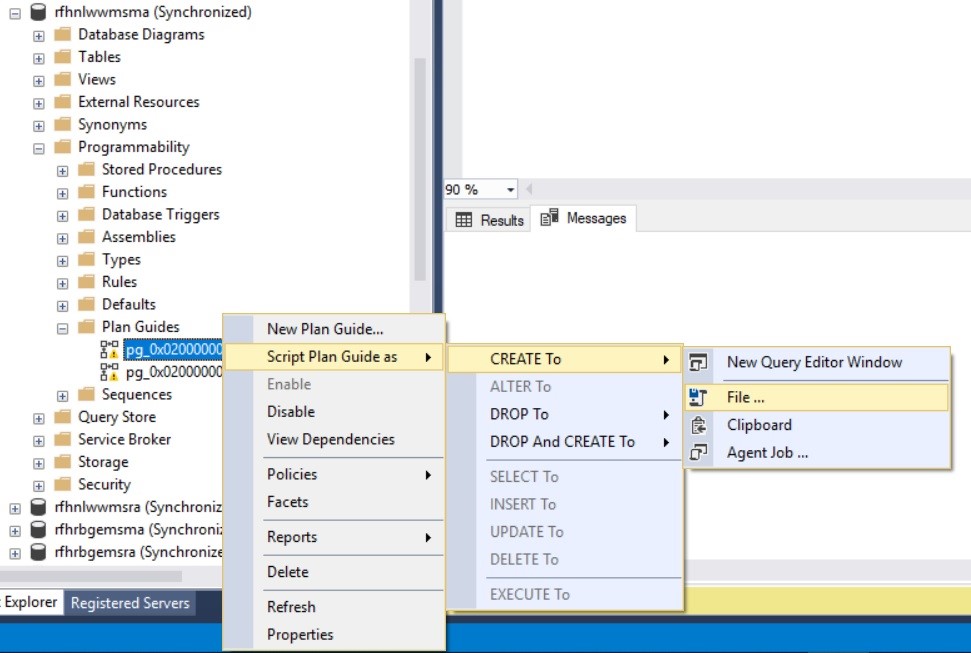
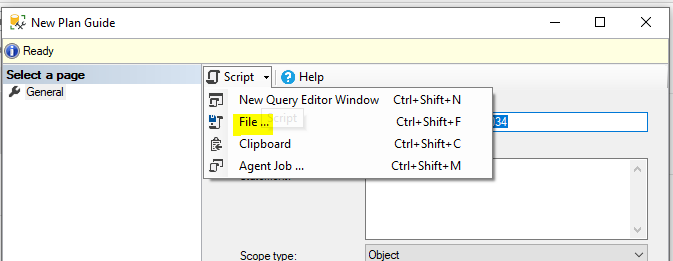
I recently used this in a case where a vendor application had a bad SQL statement in it that didn’t use the index. The table was deemed too small for index usage by SQLservers optimizer, but the subsequent tablescan led to extensive blocking in a splitsecond environment. Being a vendor application I couldn’t change the SQL statements and after examining some alternatives a planguide was considered the appropriate way. So i changed the table statistics to have a large pagecount and the optimizer was convinced that an index was best now. I captured the new executionplan with the indexusage into a planguide (the howto of that can be found here )
To reset the pagenumber use the command
DBCC UPDATEUSAGE ( 0, <tablename>)
This command can help you to find the threshold of plan changes ( called ‘tipping point’ ) See Kimberly Tripps post for an intro: https://www.sqlskills.com/blogs/kimberly/the-tipping-point-query-answers/
Mind you that the ‘tipping point’ depends on a lot of variables, such as MAXDOP settings, SQLserver version, optimizer version etcetera. You need some time in the lab when you need to find the tipping point for your table.